
Introduction:
In the field of Natural Language Processing (NLP), the development of effective algorithms for understanding the meaning and context of natural language is a critical challenge. One of the latest breakthroughs in this field is Bidirectional Encoder Representations from Transformers (BERT), an algorithm developed by Google. In this blog post, we will explore the concept of BERT, how it works, and its applications.
What is BERT?
BERT is a pre-trained natural language processing algorithm that can be fine-tuned for various NLP tasks such as question answering, sentiment analysis, and more. It is based on the Transformer architecture, which was introduced in a paper by Vaswani et al. in 2017. The Transformer architecture is a neural network architecture that can be used for sequence-to-sequence tasks such as language translation.
BERT is pre-trained on a large corpus of text data. This allows it to capture the context and meaning of words and phrases in natural language. It is unique because it is a bidirectional model, meaning it can look at both the left and right context of a word in a sentence. This makes BERT more powerful than previous language models. Which could only look at the left or right context of a word.
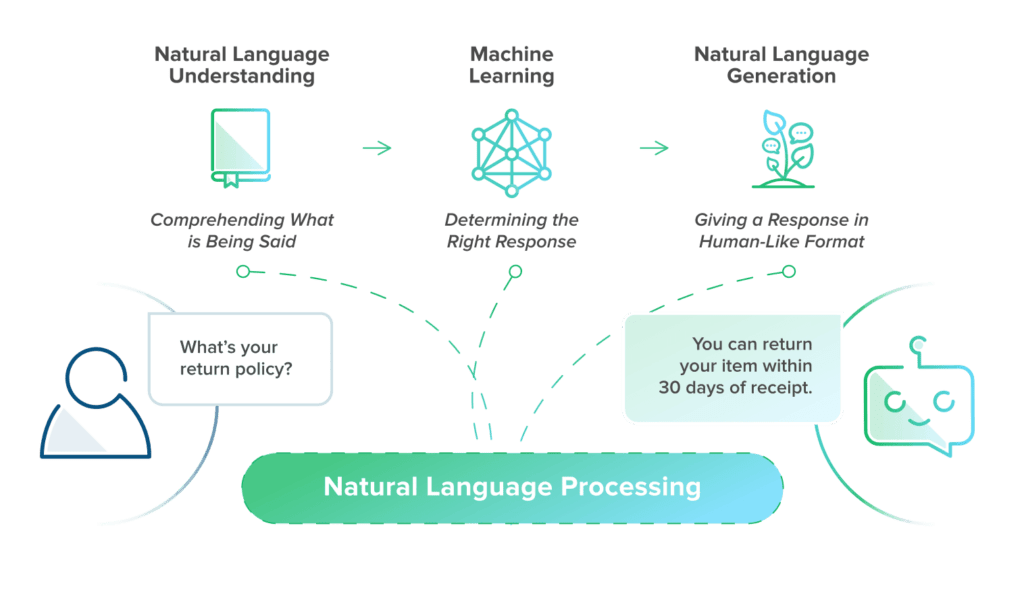
How does BERT work?
BERT is a deep learning algorithm that is trained on a massive amount of text data. During training, It learns to predict missing words in a sentence, given the context of the surrounding words. It does this by using a process called masked language modeling. In masked language modeling, BERT randomly masks some of the words in a sentence and then tries to predict what the missing words are.
After pre-training, BERT can be fine-tuned for specific NLP tasks. For example, to perform sentiment analysis, It can be trained on a dataset of labeled text data where each example has a sentiment label (positive, negative, or neutral). During training, It learns to associate the context and meaning of the text with the corresponding sentiment label.
Applications of BERT:
Bidirectional Encoder Representations from Transformers has a wide range of applications in the field of NLP. Here are some examples:
- Question Answering: BERT can be used to answer questions based on a given context. For example, Bidirectional Encoder Representations from Transformers can be trained on a dataset of questions and answers, where each question has a corresponding answer. During training, It learns to understand the context of the question and use that context to generate the correct answer.
- Sentiment Analysis: BERT can be used to perform sentiment analysis on text data. During training, BERT learns to associate the context and meaning of the text with the corresponding sentiment label.
- Text Classification: BERT can be used for text classification tasks such as topic classification and spam detection. For example, Bidirectional Encoder Representations from Transformers can be trained on a dataset of text data where each example has a corresponding label (e.g. topic, spam/ham). During training, It learns to understand the context and meaning of the text. It then uses that understanding to classify new text data.
- Named Entity Recognition: BERT can be used for named entity recognition tasks, where the goal is to identify and classify named entities in text data. For example, Bidirectional Encoder Representations from Transformers can be trained on a dataset of text data where each example contains named entities such as person names, locations, and organizations. During training, It learns to identify and classify these named entities.
Leave a Reply